Large Vision-Language Models (LVLMs) can understand the world comprehensively by integrating
rich information from different modalities, achieving remarkable advancements on various multimodal
downstream tasks. However, deploying LVLMs is often problematic due to their massive computational/energy
costs and carbon consumption. Such issues make it infeasible to adopt conventional iterative global pruning,
which is costly due to computing the Hessian matrix of the entire large model for sparsification.
Alternatively, several studies have recently proposed layer-wise pruning approaches to avoid the expensive
computation of global pruning and efficiently compress model weights according to their importance within
a layer. However, they often suffer from suboptimal model compression due to their lack of a global perspective.
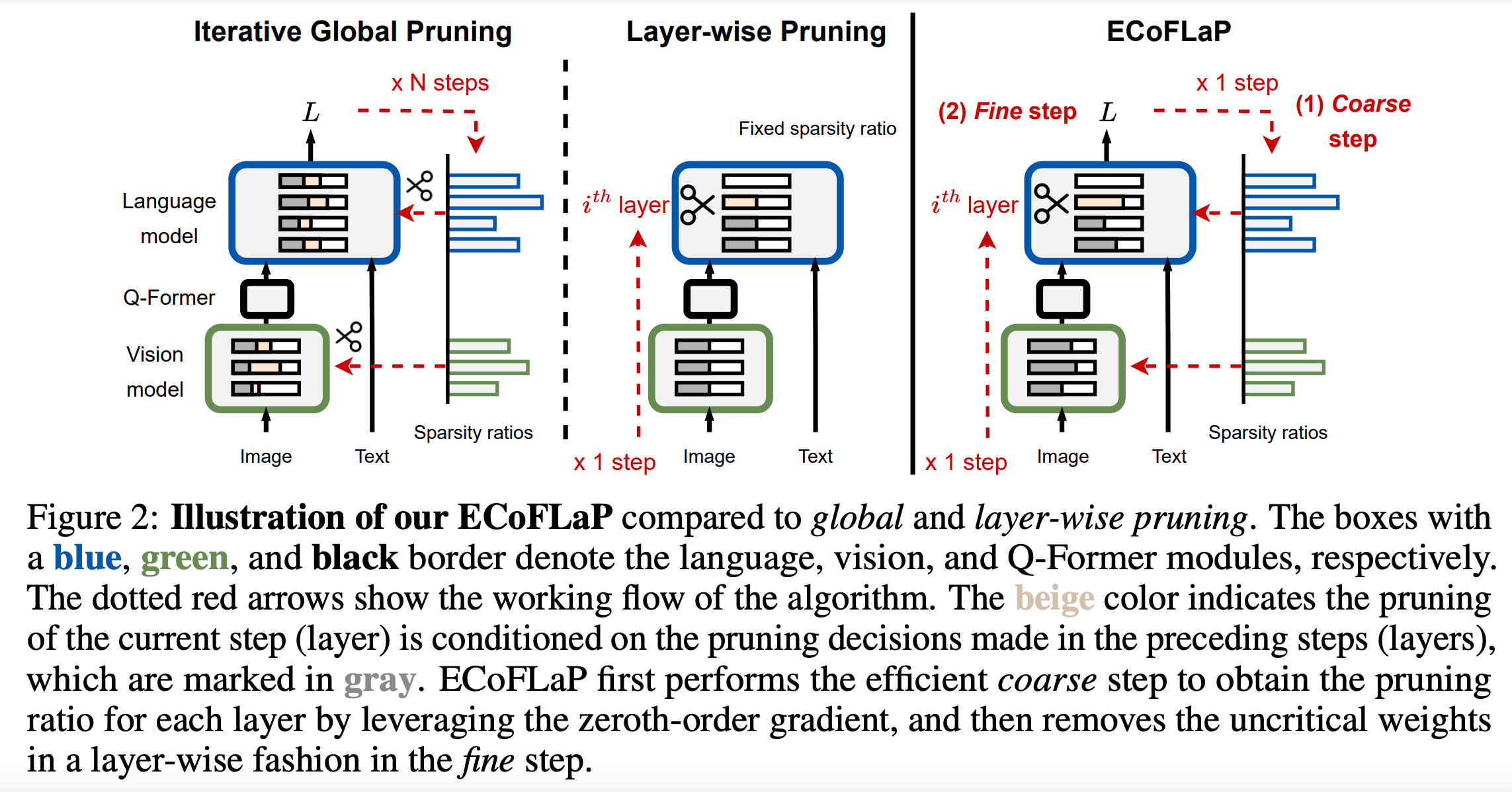
To address this limitation in recent efficient pruning methods for large models, we propose Efficient
Coarse-to-Fine LayerWise Pruning (ECoFLaP), a two-stage coarse-to-fine weight pruning approach for LVLMs.
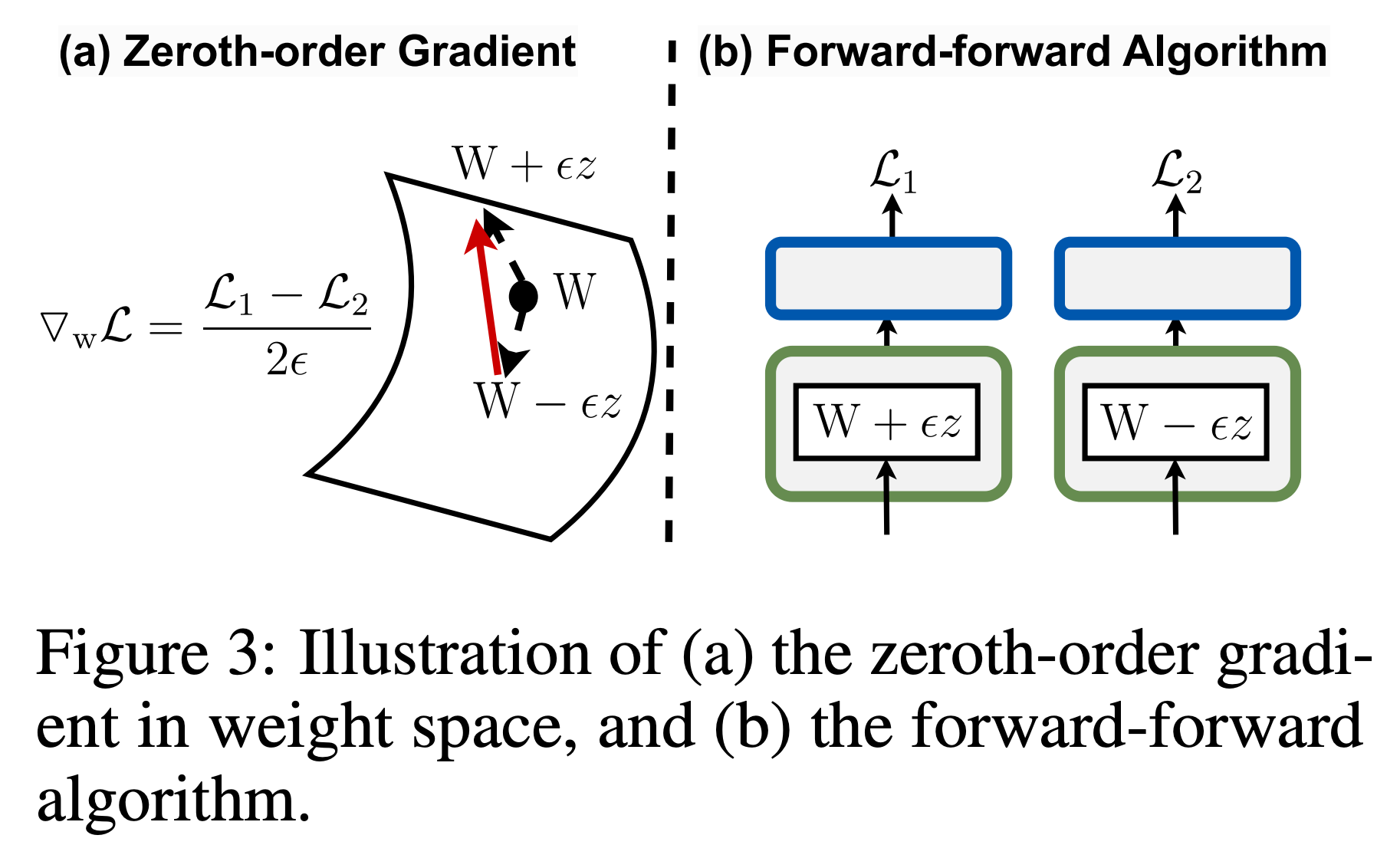
We first determine the sparsity ratios of different layers or blocks by leveraging the global importance score,
which is efficiently computed based on the zeroth-order approximation of the global model gradients.
Then, the model performs local layer-wise unstructured weight pruning based on globally-informed sparsity
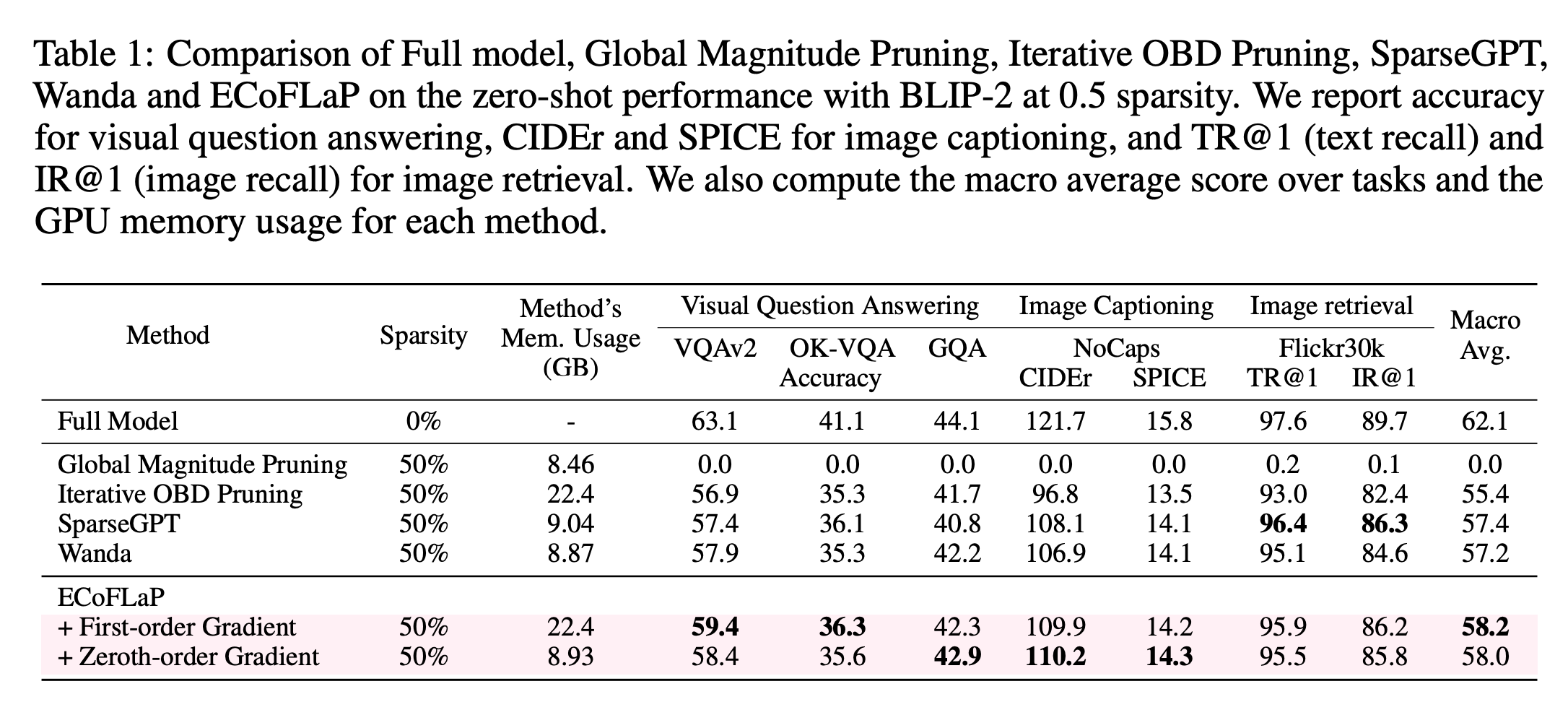
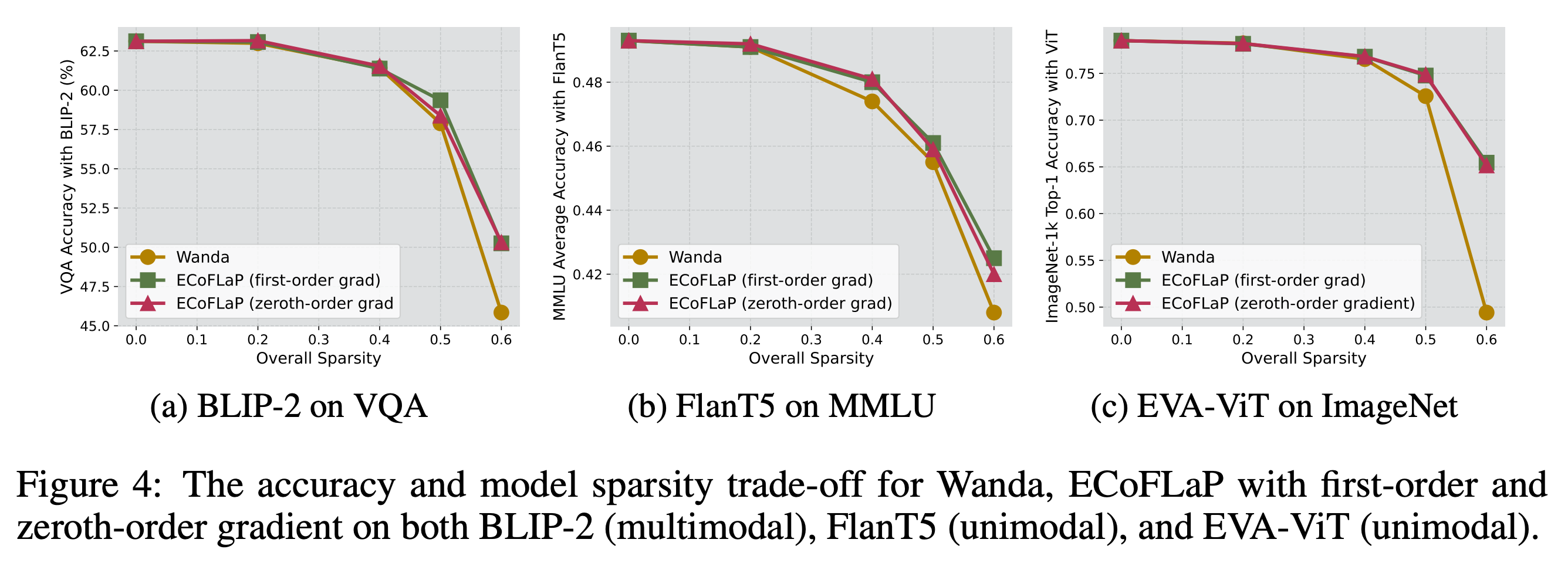
ratios. We validate our proposed method across various multimodal and unimodal models and datasets,
demonstrating significant performance improvements over prevalent pruning techniques in the high-sparsity regime.